Identification Quality Experiment Update
Hey folks, just checking in re: the Identification Quality Experiment. I really appreciate everybody's help. We now have over 3,000 expert IDs to start doing some analyses. Based on the data so far, 92% of the sample of observations were correctly ID'd. This is relative to the expert's IDs and assumes the expert is always right, which as @rcurtis, @charlie and others have mentioned isn't always the case, but lets assume its generally true.
One of my main questions is whether we can quantify how the accuracy of iNat observation's (that is the probability that they are properly identified) varies based on the contributions of the 'crowd' of IDers. My hunch is that 'earned reputation' of individual identifiers can be a pretty good indicator of whether an observation is properly ID'd or not. For example, if I've properly ID'd ladybirds a lot in the past (at least relative to the opinion of the community) does that mean that future observations that I identify as ladybirds are more likely to be properly identified? My hunch is yes, but in order to prove / quantify / model the relationship, we need a set of expert-identified observations (which is where your contributions to this experiment come in).
Let me first provide some background to my thinking about 'earned reputation'. I've grouped identifications on the site into four categories. Lets say an observation has a community ID of 'Ladybird Family'. The community ID is the consensus identification that emerges from everyone's IDs and dictates where an observation hangs on the tree of life. If I add an identification of 'Seven-spotted-ladybird'. This would be a 'Leading' identification since it is of a descendant of the community ID, but one that hasn't yet been corroborated by the community.
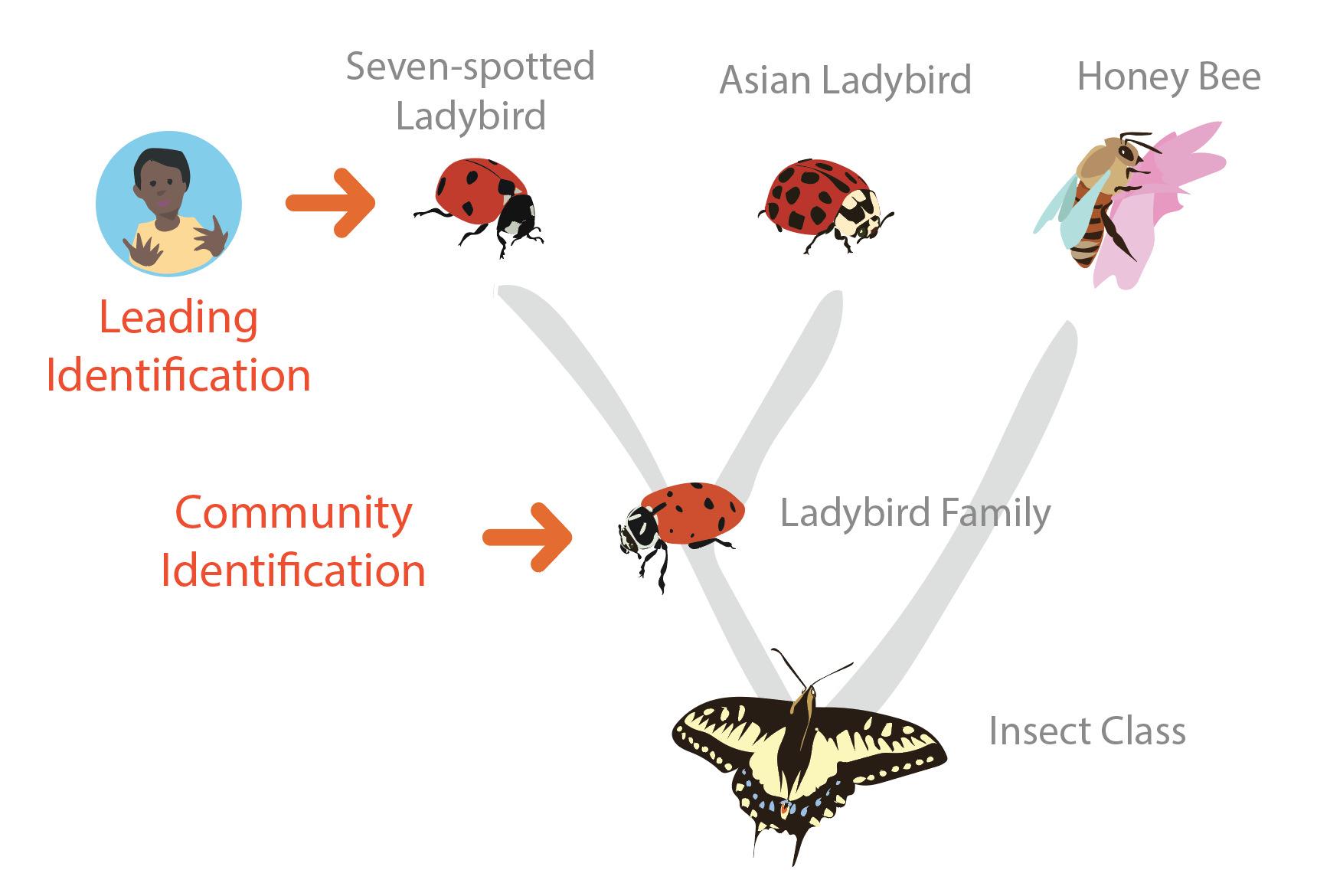
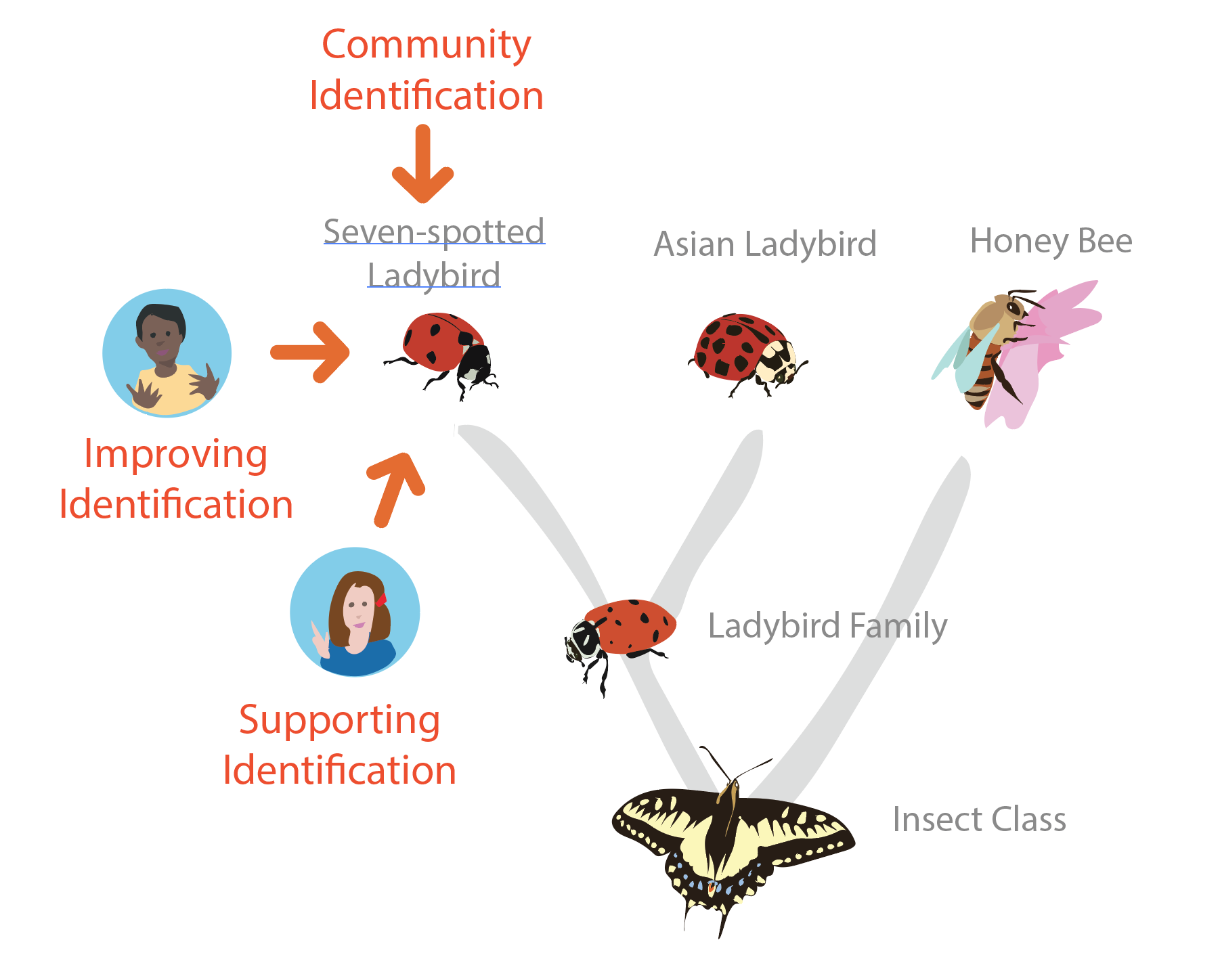
Lets imagine that enough people corroborate my 'Leading' identification that the community ID moves from 'Ladybird Family' to 'Seven-spotted-ladybird'. This would then become an 'Improving' identification because it is one that moved the community ID ball forward (ie it was the first suggestion of a taxon that the community later agreed with). I'm referring to the corroborating IDs as 'Supporting' identifications. They helped move the community ID from 'Ladybird Family' up to 'Seven-spotted-ladybird' but they didn't provide any novel suggestions.
Lastly, lets say I proposed something that the community disagrees with. For example, lets say I added an ID of 'Honey Bee' but there was still enough community weight for 'Ladybird Family' that the community ID remained there. Because my ID of 'Honey Bee' is a lateral sibling to the community ID (rather than a descendant or ancestor) lets call it a 'Maverick' identification. This doesn't mean I'm necessarily wrong, but it does mean I'm out of step with the community.
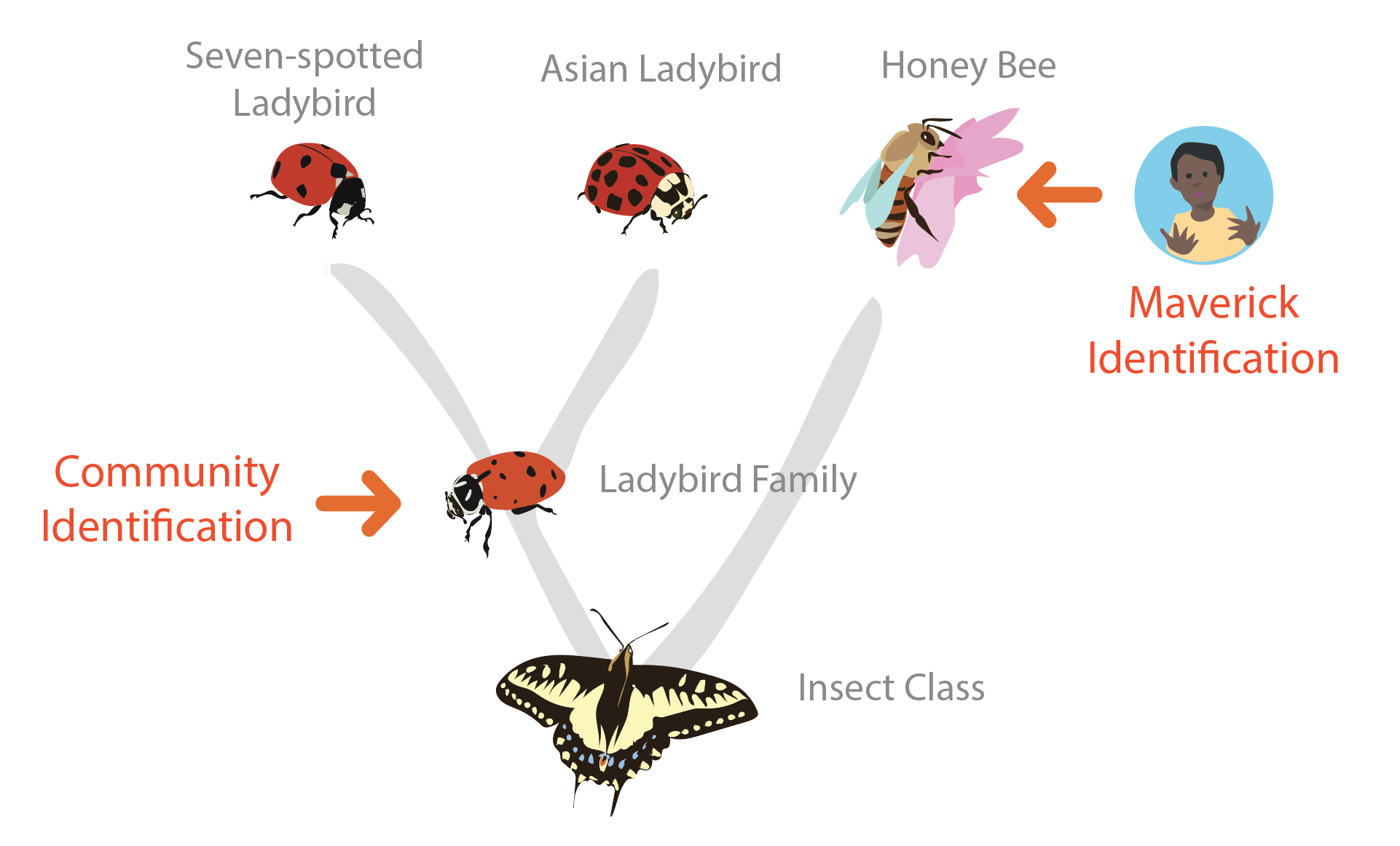
Now lets imagine that there was an observation of 'Ladybird Family' on iNaturalist and all we know about it is that it was identified by me. Lets call the number of times in the past that I made 'Improving' identifications of ladybird 'wins' (that is the times that I was the first to propose ladybird and the community later backed me up). Similarly, lets call the number of times in the past that I made 'Maverick' identifications of ladybirds 'fails'. Lets say my track-record for Ladybirds was 30 wins and 1 fail. Is there a correlation between this earned reputation and the probability that the observation ID'd by me as a ladybird is properly IDed?
The graph below shows all ~3,000 observations in the 'expert ID' sample as points colored by whether they were properly ID'd (gray) or improperly ID'd (black) relative to the expert-opinion. The x-axis shows the total number of 'wins' summed across all the identifiers contributing to that observation before it was assessed by the expert in this experiment. For example, if an observation was ID'd be me and charlie, the community ID was 'Carrot Family' and charlie and I together had 300 'wins' from past observations of carrots we'd ID'd, then the observation would sit around 300 on the x-axis. Similarly, the y-axis shows the number of 'fails' summed across all identifiers. The colors increasing from blue to red is the modeled probability that an observation is properly ID'd based on the number of win's and fails.
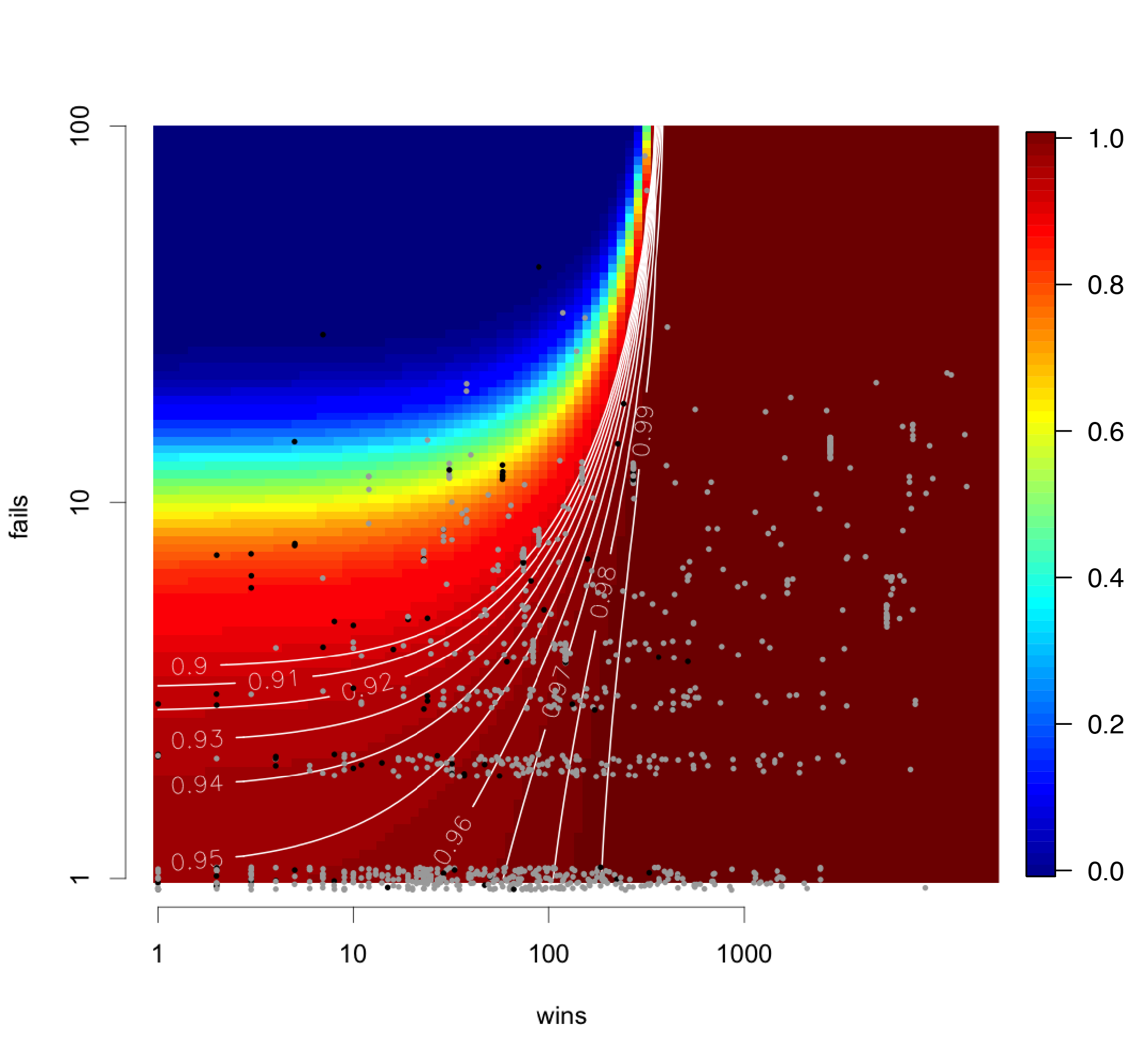
The model shows that there is a strong correlation between the number of wins and fails from the community of IDers and the probability that an observation is properly ID'd. For example, while the model suggests that an observation ID'd by a community with 0 wins and 0 fails (e.g. we know nothing about their earned reputation for that taxon) is 96% correct (lower left of the graph), an observation ID'd by a community with 200 wins and 0 fails for that taxon is 99% correct. Similarly, an observation ID'd by a community with 10 wins and 10 fails is 62% correct.
2-caveats: first, we know that the expert-IDs aren't always right so there's reasons the community is probably performing better than this model would indicate. But similarly, ID's aren't all independent (there's some group-think) so the community might be performing slightly worse than this model would suggest (which assumes IDs are independent). Second, we know there's a lot of other factors at play here. Other observation characteristics like location and type of taxa probably influence probability that obs are properly ID'd.
But as a simple, first-order approach. This study seems to indicate that there is a strong correlation between taxon-specific past earned-reputation among the identifiers of an observation and the probability that the observation is properly identified. This makes intuitive sense, but its cool we can quantify it. It would be pretty neat to use something like this to be a bit more rigorous and quantitative about the 'Research Grade' threshold which currently is pretty naive. We could also use something like this to try to speed up getting observations to 'Research Grade' status by putting them in front of the right identifiers (who we can target based on this passed earned-reputation). But there are also ways that this kind of system could bother people. Maybe it unintentionally gamifies things in a way that undermines the process. Or maybe its too black box and turns people off ('why is this observation Research Grade and this one not?').
Curious to hear you're thoughts. Also 3k is still a relatively small sample so would love to repeat this analysis with more IDs. So if you have the skills to help and haven't already joined the Identification Quality Experiment please do. And if you have joined, please add as many ID's through the interface as possible. Also curious to hear other thoughts on whats working / whats not working with the experiment. I know there's some concern about things like (a) ambiguous subjects of photos, and (b) accidentally stomping finely ID'd obs with coarser IDs. I'd like to find ways round these issues, but in the short term, skipping problematic obs should suffice.
Thanks again!
Scott
@charlie @fabiocianferoni @vermfly @jennformatics @d_kluza @arachnojoe @cesarpollo5 @ryanandrews @aztekium @lexgarcia1 @harison @juancarlosgarciamorales1 @garyallport @echinoblog @jrwatkin68 @bryanpwallace @wolfgang_wuster @bobdrewes



Comentarios
wow, fascinating! Thanks! Admittedly i'd been slacking on this some because i was trying to see all the new spring observations including the 'ambiguous' ones but i will keep working on it when i get a chance.
i think my error rate is actually a little higher on this than normal IDs. Firstly, sometimes the wrong species is identified, some peple have let me know, but others probably wouldn't. Secondly, the comments with the observations often have habitat info, scent, other stuff like that, which helps. And thirdly, with difficult IDs there's often a lot of community discussion. But i guess that's all just a rehash of what has already been discussed. Anyway... very neat!
also did you change how the algorithm worked? Because it's now really excited about showing me lots of red spruce, rather than being in order posted. Very interesting!
Very cool! Now that the semester is over, I'll get our crew finishing up our set of IDs.
@charlie I always wonder what species its going to show me a lot of... there's usually a variety, but always one species that it shows a ton of. Right now its American Coots...
Also, very interesting to see the data coming from this! I'll keep on making IDs when I find time.
I'm really interested in this new algorithm if it's looking for things I've IDed before. How neat.
also: i am not flagging the ambiguous ones as reviewed, because if i do it will flag them as such for me on the whole site, right? Like one when i see several plants and the description may say? Because i may be able to ID them later the other way
I think the experiment is paying off. Really hard to get a right way to identify with a big community as ours, but it's great to look for options.
It makes me so happy to know that our observations and photos will feed a data base able to help automatically with the ID's , giving us some more time to do more observations and also some more research.
Glad to be part of this and I'll keep doing it.
If all this effort can help to make the identification process better and more accurate , and the resulting Guides and Data are easy to reach that's good enough for me.
Saludos, Scott.
I am sorry, I did not continued to contribute to the experiment, is still time to continue?, can we invite some other people?
Just a question, is this going to change the way id counter works on the people page?
as far as i know the experiment is still going
yes - still going! Please add as many ID's as you can (skipping ones with ambiguous subjects or where you can't ID to species is probably best for now). we're at ~4k 'expert IDs' but would be great to have an even larger sample. I'll provide another update soon. My main questions are:
Question 1: How accurately are observations ID'd?
Question 2: What is the relationship between an identifiers (empirical earned) reputation and observation ID accuracy
Question 3: What is the average RG grade accuracy? And how does this differ from predicted accuracy for RG obs?
Question 4: How could (empirical earned) reputation weights be introduced into the community ID (CID) to optimize the rank and accuracy of the CID (down the road).
The ID counter is currently just counting all IDs. Could count IDs differently, but that wasn't one of the immediate goals of this experiment.
Just seeing this now. Neat.
i ended up having a much larger error rate on this than my regular IDs i think. Turns out the notes, ID of the user and that other info actually is raelly helpful in finding the context and setting. I stopped doing it because i was really annoying people by IDing the wrong thing - with plants there is almost always more than one in the image. That being said i AM interested in the results!
I'm just seeing this post now - very cool. Is the experiment still going? I checked in and it does not appear to be loading observations. I had one cases where my ID differed from the community and where the community was right and I was wrong, and another where I put a species-level ID that differed from the community where the only reasonable ID (on reflection) was to family level.
I didn't get to finish mine either; got busy and didn't have time to consult with the other folks I was going to bring in. Would love it if another round came about some time. And would also love to see updated results, if any!
Mavericks can be maverick because they are an initial id and wrong, or they can be maverick because they are an expert and correcting a frequently mis-id species for which alternate identifications are rarely known. Improving ids can get supported because they're right and verified afterwards, or they can get high support because they are the single well known id for a frequently mis-id'd taxon, which might also be why they were suggested. So this can work for removing or worsening bias, depending on which type of pattern is more common.
Añade un comentario